
RDS for Oracleにダンプファイルをインポートしてみる【AWS】

この記事ではRDS上にあるダンプファイルをRDSに実際にインポートする方法を紹介します。
RDSに転送する方法、ダンプファイルを作成する方法は下記を参考にしてください。
・RDS上にあるダンプファイルをインポートしたい。
RDS上に格納されたダンプファイルを確認
下記コマンドにRDS上にダンプファイルが格納されているのを確認します。
SELECT * FROM TABLE (RDSADMIN.RDS_FILE_UTIL.LISTDIR(P_DIRECTORY => 'DATA_PUMP_DIR'));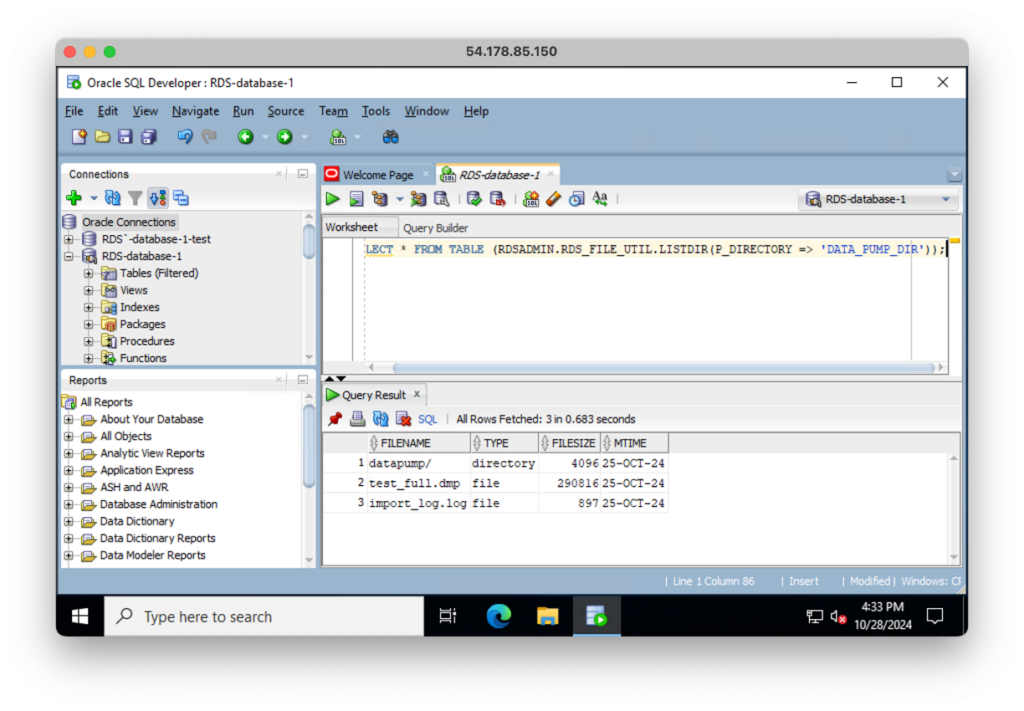


RDS上のdumpファイルをインポートする。
ディレクトリを作成します。なんでも良いですが下記で用意します。
/home/ec2-user/work/sql下記のコードをsqlファイルで保存します。
vi schema_full.sql記述する内容は下記を参考。<YOUR_DUMPFILE_NAME>はダンプファイル名を指定してください。
DECLARE
h1 NUMBER; -- ジョブハンドル
BEGIN
-- インポートジョブの作成(FULL = N、SCHEMA レベルのインポート)
h1 := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => NULL);
-- ダンプファイルの指定
DBMS_DATAPUMP.ADD_FILE(handle => h1, filename => '<YOUR_DUMPFILE_NAME>', directory => 'DATA_PUMP_DIR');
-- ログファイルの指定(必要に応じて)
DBMS_DATAPUMP.ADD_FILE(handle => h1, filename => 'import_log.log', directory => 'DATA_PUMP_DIR', filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_LOG_FILE);
-- インポートのパラメータを設定(例えば、存在するオブジェクトを上書きする場合)
DBMS_DATAPUMP.METADATA_FILTER(handle => h1, name => 'EXCLUDE_PATH_EXPR', value => 'IN (''TABLE'')');
DBMS_DATAPUMP.SET_PARAMETER(handle => h1, name => 'TABLE_EXISTS_ACTION', value => 'REPLACE');
-- インポートジョブの実行
DBMS_DATAPUMP.START_JOB(h1);
END;
/今回でいうと下記の内容です。
(今回は省略しましたが、インポートする前に表領域とユーザー作成、表領域割り当てしておくことが必要です。)
DECLARE
h1 NUMBER; -- ジョブハンドル
BEGIN
-- インポートジョブの作成(FULL = N、SCHEMA レベルのインポート)
h1 := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => NULL);
-- ダンプファイルの指定
DBMS_DATAPUMP.ADD_FILE(handle => h1, filename => 'test_full.dmp', directory => 'DATA_PUMP_DIR');
-- ログファイルの指定(必要に応じて)
DBMS_DATAPUMP.ADD_FILE(handle => h1, filename => 'import_log.log', directory => 'DATA_PUMP_DIR', filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_LOG_FILE);
-- インポートジョブの実行
DBMS_DATAPUMP.START_JOB(h1);
END;
/importログの確認コマンド
下記importログ確認コマンドよりダンプファイルのインポート状況をモニタリングできます。
今回はデータが少ないので、すぐ終わりました。
SELECT TEXT FROM TABLE(RDSADMIN.RDS_FILE_UTIL.READ_TEXT_FILE('DATA_PUMP_DIR' ,'import_log.log'));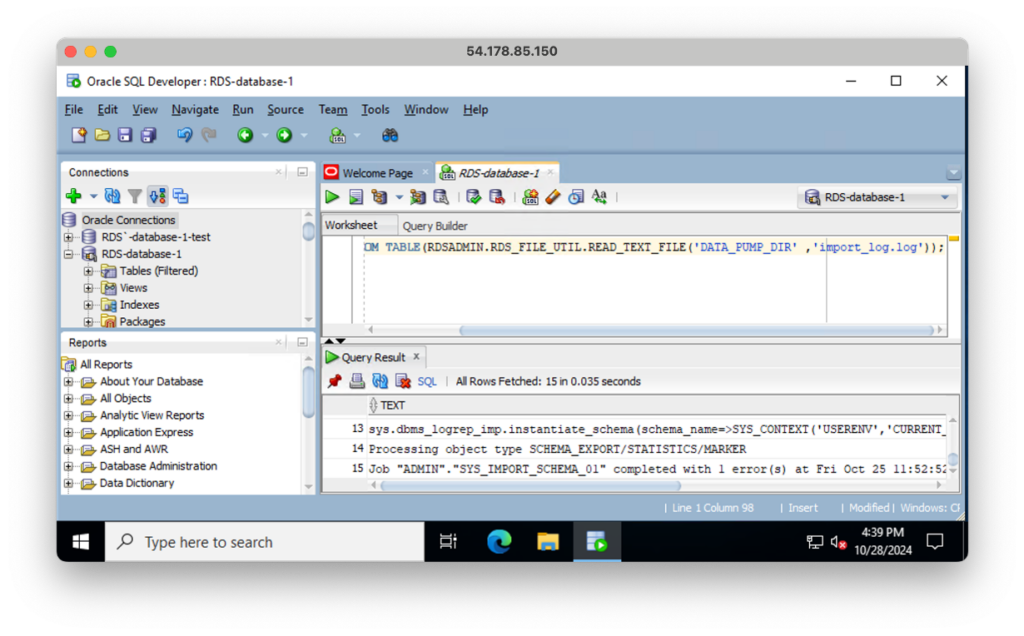
一件エラーができているようですが「conmlete with」と表示されれば問題ありません。
テーブル確認
下記コマンドよりテーブルを確認。
select
table_name,
to_number(
extractvalue(
xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name))
,'/ROWSET/ROW/C')) count
from user_tables
WHERE TABLE_NAME NOT LIKE 'BIN$%'
and (iot_type != 'IOT_OVERFLOW' or iot_type is null)
order by table_name;無事にインポートできました。
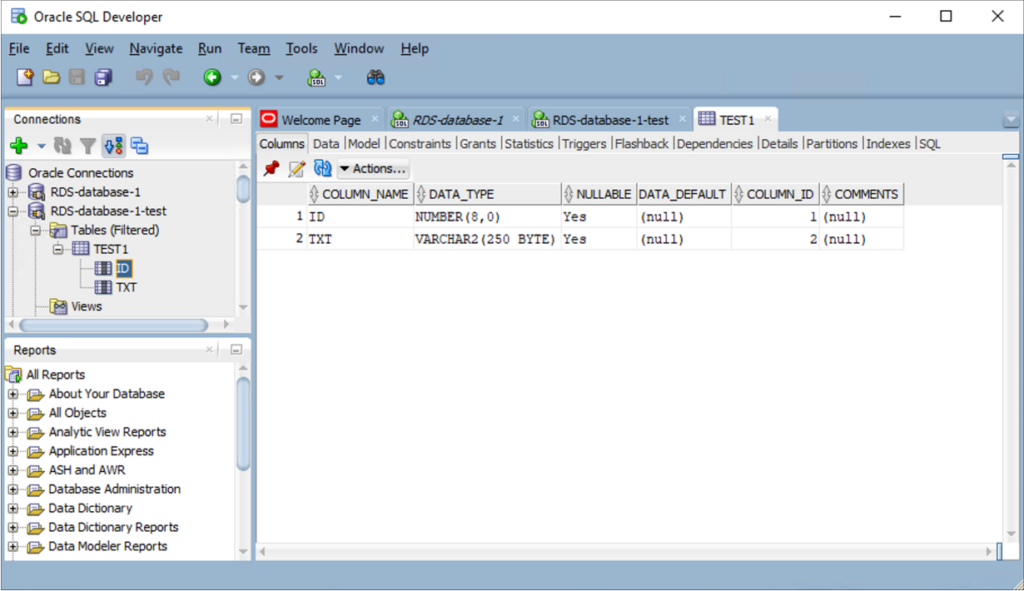
今回EC2上に作成したDBが無事インポートできるのを確認できました!
本来であればデータ件数、index、シーケンスも確認した方が良いですが、今回は実験なので
テーブル確認のみとします。
以上です、誰かの参考になれば幸いです。